
JVM相关问题
JVM垃圾回收时如何确定是垃圾?什么是GC Roots
- 引用计数法,判断是否被引用(解决不了循环引用问题)
- 可达性分析(根搜索路径GC Roots)
- **基本思路就是通过一系列名为GC Roots的对象为起始点。**往下搜索,如果一个对象和GC Roots没有任何引用链相连时,说明对象不可用。
- 哪些可以成为GC Roots
虚拟机栈java stack中引用的对象方法区Method Area中的类静态属性引用的对象方法区Method Area常量引用的对象本地方法栈中(native方法)引用的对象
public class GcRootsDemo {
private static GcRootsDemo2 t2;//2.方法区类静态属性引用对象
private static GcRootsDemo3 t3 = new GcRootsDemo3();//3.方法区常量引用的对象
private byte[] byteArrays = new byte[100 * 1024 * 1024];//4.native对象
public static void m1() {
GcRootsDemo t1 = new GcRootsDemo();//1.java stack中引用的对象
System.gc();
System.out.println("第一次GC完成");
}
public static void main(String[] args) {
m1();
}
}
如何查看JVM参数默认值(JVM的参数类型)
标配参数
- -version
- -help
- -showversion
x参数(了解)
- -Xint 解释执行
- -Xcomp 第一次使用就编译成本地代码
- -Xmixed 混合模式
xx参数
jps -l 找进程号, jinfo查看配置布尔类型 (公式:-XX:+某属性 -XX:-某属性 +开启 -关闭)
- 比如
jps -l找到一个类进程号,然后jinfo -flag PrintGCDetails 进程号,查看是否开启了开始GC收集PrintGCDetails(可以通过 -XX:+PrintGCDetails 设置)。 jinfo -flag UseSerialGC 进程号查看是否使用串行GC
- 比如
KV设值类型
- 假设我们看
元空间MetaSpace大小,也可以先用布尔参数查询,jinfo -flag MetaspaceSize 进程号获取查看。此时我们设置自己想要的大小-XX:MetaspaceSize=128m,再次进行查看 - 同样可以查看设置新生代到老年代的年龄
MaxTenuringThreshold
- 假设我们看
jinfo -flags 进程号可以查询所有的可调整的区域的参数名
Non-default VM flags: -XX:CICompilerCount=4 -XX:InitialHeapSize=266338304 -XX:MaxHeapSize=4242538496 -XX:MaxNewSize=1414004736 -XX:MinHeapDeltaBytes=524
288 -XX:NewSize=88604672 -XX:OldSize=177733632 -XX:+PrintGCDetails -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamp
s -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC //默认的
Command line: -XX:+PrintGCDetails //人工配置的
-Xms -Xmx
- -Xms 等价于 InitialHeapSize
- -Xmx 等价于 MaxHeapSize
java -XX:+PrintFlagsInitial查看JVM初始化参数值java -XX:+PrintFlagsFinal -version打印最终值,如果某个默认值被新值覆盖,显示新值(其中有:=标记的,说明是被用户或者JVM修改过的参数)java -XX:+PrintCommandLineFlags -version常用的参数配置以及GC的默认垃圾回收器
-XX:InitialHeapSize=265147264 -XX:MaxHeapSize=4242356224 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLarge
PagesIndividualAllocation -XX:+UseParallelGC //默认垃圾回收器
常用的JVM参数配置有哪些
-Xms -Xmx- Xms 默认是物理内存的1/64
- Xmx 默认是物理内存的1/4
-Xss等价 -XX:ThreadStackSize,一般默认 512k~1024k-Xmn设置年轻代大小(一般不需要调整) 新生代老年代比例1/3,2/3-XX:MetaspaceSize元空间,jdk8以后,这个空间不占用heap的内存,大小取决与机器内存- 虽然是占用物理内存,但是会有默认值,为了避免元空间OOM,可以把这个参数设置大一点(允许的话 512MB ~ 1G范围)
-XX:+PrintGCDetails收集GC详细日志输出信息
强引用、软引用、弱引用、虚引用
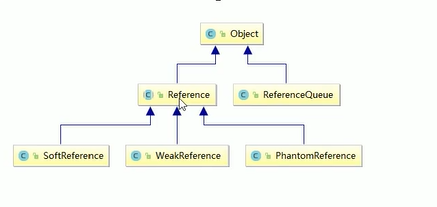
强引用Reference默认支持模式- 当内存不足,JVM开始GC,对于强引用对象,就算是出现了OOM也不会对对象进行回收。
- 强引用就是我们常见的普通对象引用(Person p = new Person();),只要有强引用指向一个对象,说明对象还活着。一个对象被强引用变量引用时,它处于可达状态,*即使该对象以后永远不会用到,也不会被GC回收。*因此强引用时造成内存泄漏的主要原因之一。
- 一个普通对象,如果它没有其它引用关系,只要超过了引用作用域或者显式的将引用赋值为null。一般认为它是可以被GC的。
public class StrongReference {
public static void main(String[] args) {
Object obj1 =new Object();//定义的默认强引用
Object obj2 = obj1;//obj2引用赋值,也指向obj1指向的内存地址
obj1 = null; //obj1指向为null
System.gc();
System.out.println(obj2);//不会被垃圾回收
}
}
软引用SoftReference- 软引用是相对强引用弱化了点的引用,需要用java.lang.ref.SoftRerence类实现,可以让内存豁免一些垃圾收集。
- 对于只有软引用的对象来说
- 当内存充足时,不会被GC
- 当内存不足时,会被GC
- 软引用通常用在内存敏感的数据中,比如高速缓存就用软引用。
public class SoftReferenceDemo {
/**
* 内存够用时
*/
public static void memory_enough() {
Object obj1 = new Object();
SoftReference softReference = new SoftReference(obj1);//软引用
System.out.println(softReference.get());
obj1 = null; //失效强引用
System.gc();
System.out.println(softReference.get() + "==");//内存够用,不GC
}
/**
* 内存不够用时
* JVM配置小内存,模拟OOM -Xms5m -Xmx5m -XX:+PrintGCDetails
*/
public static void memory_not_enough() {
Object obj1 = new Object();
SoftReference softReference = new SoftReference(obj1);//软引用
System.out.println(softReference.get());
obj1 = null; //让引用失效
try {
byte[] b = new byte[30 * 1024 * 1024];
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println("soft->"+softReference.get()); //不够用被回收null
}
}
public static void main(String[] args) {
memory_enough();
memory_not_enough();
}
}
弱引用WeakReference- 弱引用需要用java.lang.ref.WeakReference实现,它比软引用生存期短。
- 对于只有弱引用的对象来说,只要垃圾回收机制运行,不管JVM内存空间是否足够,都会被回收
public class WeakReferenceDemo {
public static void main(String[] args) {
Object o1 = new Object();
WeakReference<Object> weakReference =new WeakReference<>(o1);
System.out.println(weakReference.get() + "--GC前");
o1 = null ;//去掉强引用
System.gc();
System.out.println(weakReference.get() + "--GC后");//被回收了
}
}
虚引用PhantomReference- 弱引用需要用java.lang.ref.PhantomReference类来实现。
- 顾名思义,就是形同虚设,与其它几种不同,虚引用并不会决定对象生命周期
- **如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可以被GC回收。**它不能单独使用,需要和
引用队列ReferenceQueue联合使用。 - PhantomReference.get()方法总是返回null,因此无法访问被引用对象。其意义在于说明一个对象已经进入了finalzation阶段,可以被gc回收,用来实现比finalzation机制更灵活的回收操作
- 换句话说,设置
虚引用PhantomReference关联的唯一目的,就是在这个对象被回收器回收时,收到一个系统通知或者后续添加进一步处理。java技术允许使用finalize()方法在垃圾回收器将对象从内存中清除出去前做必要的清理工作(相当于AOP中的后置通知)。
引用队列ReferenceQueue
/**
* 引用可以单独使用,也可以配合ReferenceQueue使用
* 如果使用了ReferenceQueue,当GC是否对象内存时,会将其加入到ReferenceQueue中
* 程序发现某个软引用、弱引用、虚引用已经被加入到队列中,意味着其指向的堆heap内存对象被回收,通过这种方式,JVM允许我们在对象被回收后做一些我们想做的事
*/
public class ReferenceQueueDemo {
public static void main(String[] args) {
Object o1 =new Object();
ReferenceQueue<Object> queue =new ReferenceQueue<>();
PhantomReference<Object> weakReference =new PhantomReference<>(o1,queue);
System.out.println(o1);//有值
System.out.println(weakReference.get());//get为空,如果换成软引用就有值
System.out.println(queue.poll());//null
System.out.println("----------------------------");
o1 =null;
System.gc();
System.out.println(o1);//null
System.out.println(weakReference.get());//null
System.out.println(queue.poll());//有值,gc后把值放入队列
}
}
软引用SoftReference 弱引用WeakReference使用场景
- 假如我们有一个应用需要读取大量图片
- 如果每次加载会严重影响性能
- 如果一次性加载到内存又可能内存溢出
- 此时软引用可以解决这个问题,设计思路用一个HashMap保存图片路径和相应图片对象关联的软引用之间映射关系,内存不足时,JVM会回收占用的空间
- 假如我们有一个应用需要读取大量图片
Map<String,SoftReference<Bitmap>> imageCache = new HashMap<String,SoftReference<Bitmap>>();
- WeakHashMap 是“弱键”实现的哈希表。它这个“弱键”的目的就是:实现对“键值对”的动态回收。当“弱键”不再被使用到时,GC会回收它,WeakReference也会将“弱键”对应的键值对删除。
public class WeakHashMapDemo {
public static void main(String[] args) {
WeakHashMap<Integer, String> weakHashMap = new WeakHashMap();
Integer k = new Integer(1);
String v = "val1";
weakHashMap.put(k, v);
System.out.println(weakHashMap);
k = null;//k失效以后
System.gc();
System.out.println(weakHashMap);//map内容被移除
}
}
OOM的认识
StackOverflowError
- 栈内存空间溢出(简单就是递归调用)
OutOfMemoryError:Java heap space
- 堆空间内存溢出,调整-Xms -Xmx
OutOfMemoryError:GC overhead limit exceeded
- 超过gc最高警戒,大部分资源都用来做gc回收了(超过98%资源都用来gc,但是回收不到2%heap内存),但是还是内存溢出
- 简单理解就是大量的new对象,导致回收不过来
(List<Integer> 循环添加 Integer对象)
OutOfMemoryError:Direct buffer memory
- 写NIO程序经常使用ByteBuffer来读取写入数据,它可以使用native函数库直接使用堆heap外内存(本地内存),然后通过一个存储在java堆heap里面的DirectByteBuffer对象作为内存的引用进行操作
ByteBuffer.allocteDirect()。如果只使用本地内存而堆内存使用很少,那JVM则不执行GC,ByteBuffer对象不会被回收,此时本地内存满了,再次尝试分配本地内存就会抛此异常。
- 写NIO程序经常使用ByteBuffer来读取写入数据,它可以使用native函数库直接使用堆heap外内存(本地内存),然后通过一个存储在java堆heap里面的DirectByteBuffer对象作为内存的引用进行操作
OutOfMemoryError:ubable to create new native thread
- 应用创建了太多线程,超出系统承载能力;或者你的服务器不允许创建这么多线程(linux默认单个进程可创建的线程数是1024个);
- 解决办法就是:降低应用创建的线程数,分析是否需要这么多线程,将线程数降低;对于确实需要创建很多线程的且超过linux默认个数的,可以修改linux配置,扩大linux限制
OutOfMemoryError:Metaspace
- 使用
java -XX:+PrintFlagsInitial命令看MetaspaceSize初始化值 - 元空间内存不足,可以尝试调整
-XX:MetaspaceSize=1024m
- 使用
生产环境服务器变慢的诊断思路、以及如何性能评估
Linux 命令
- 整机:
top查看cpu和内存占用情况- 查看右上角系统负载load average三个值(分别代表系统1分钟5分钟15分钟评价负载值):如果三个数相加除3乘100% > 60%,说明负载较高
uptime是精简版
[root@iZbp1f96jelc5vbwqq8habZ ~]# top
top - 15:33:29 up 175 days, 7 min, 1 user, load average: 0.03, 0.08, 0.03
Tasks: 127 total, 3 running, 124 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.4 us, 0.7 sy, 0.0 ni, 97.3 id, 0.0 wa, 0.7 hi, 0.0 si, 0.0 st
MiB Mem : 1827.0 total, 98.1 free, 1555.5 used, 173.5 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 114.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2528486 root 10 -10 172348 14048 2320 S 1.0 0.8 269:14.93 AliYunDun
1806 root 20 0 2461016 162656 0 S 0.3 8.7 170:27.97 java
43823 mysql 20 0 1355804 393768 0 S 0.3 21.0 1043:15 mysqld
176259 rabbitmq 20 0 1728248 82408 528 S 0.3 4.4 549:16.42 beam.smp
3593818 root 20 0 67436 3056 2260 R 0.3 0.2 0:00.46 top
1 root 20 0 244704 4952 1928 S 0.0 0.3 5:29.53 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:02.26 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-kblockd
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 2:05.13 ksoftirqd/0
10 root 20 0 0 0 0 R 0.0 0.0 14:30.61 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
12 root rt 0 0 0 0 S 0.0 0.0 0:00.99 watchdog/0
13 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0
15 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
16 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 netns
17 root 20 0 0 0 0 S 0.0 0.0 0:01.30 kauditd
18 root 20 0 0 0 0 S 0.0 0.0 0:09.74 khungtaskd
19 root 20 0 0 0 0 S 0.0 0.0 0:00.00 oom_reaper
20 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 writeback
21 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kcompactd0
22 root 25 5 0 0 0 S 0.0 0.0 0:00.00 ksmd
23 root 39 19 0 0 0 S 0.0 0.0 2:38.96 khugepaged
- CPU:
vmstat查看cpu(包含不限于)- 主要看procs和cpu
- procs中r是运行b是阻塞
- r 运行和等待cpu时间片的进程数((7+0+2)/3),原则上1核cpu运行队列要超过2,整个系统运行队列不能超过总核数的2倍,负责代表系统压力大
- b 等待资源的进程数,比如等待磁盘IO 网络IO等
- cpu
- us 用户进程消耗cpu时间百分比,us值高,用户进程消耗CPU时间多,如果长期大于50%,优化程序
- sy 内核进程消耗cpu时间百分比
- us + sy 如果大于80(即80%)说明存在cpu不足
- procs中r是运行b是阻塞
- 额外查询
- 查所有cpu核信息
mpstat -P ALL 2 - 查具体进程cpu用量
pidstat -u 1 -p 进程号
- 查所有cpu核信息
- 主要看procs和cpu
[root@iZbp1f96jelc5vbwqq8habZ ~]# vmstat -n 2 3 //每两秒采样一次,共计三次
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
7 0 0 93436 0 182224 0 0 29 8 2 2 2 2 97 0 0
0 0 0 93376 0 182224 0 0 0 0 640 1663 2 2 96 0 0
2 0 0 93376 0 182228 0 0 0 9 675 1705 2 2 96 0 0
- 内存:
free应用程序可用的内存数- 应用程序可用/系统物理内存 > 70% 内存充足
- 应用程序可用/系统物理内存 < 20% 内存不足
- 额外查询
pidstat -p 进程号 -r 采样间隔秒数
[root@iZbp1f96jelc5vbwqq8habZ ~]# free -m //MB单位显示
total used free shared buff/cache available
Mem: 1826 1566 95 13 165 101
Swap: 0 0 0
- 硬盘:
df查看磁盘剩余
[root@iZbp1f96jelc5vbwqq8habZ ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 899M 0 899M 0% /dev
tmpfs 914M 60K 914M 1% /dev/shm
tmpfs 914M 652K 913M 1% /run
tmpfs 914M 0 914M 0% /sys/fs/cgroup
/dev/vda1 40G 7.1G 33G 18% /
tmpfs 183M 0 183M 0% /run/user/0
overlay 40G 7.1G 33G 18% /var/lib/docker/overlay2/c35afb1b262c3b56af10b0ca667cbc2429f5dee881494ed34c185b7b80eece5f/merged
shm 64M 0 64M 0% /var/lib/docker/containers/88b53c86c3bb7c1a22417ff2776b76ca18f49d102b88145febfaa274a7515f1c/mounts/shm
overlay 40G 7.1G 33G 18% /var/lib/docker/overlay2/74673bee00adfa946eba8a2182fdaab921bb44d867885c318d265531db45a25f/merged
shm 64M 0 64M 0% /var/lib/docker/containers/d216f33687c30c2412dfba04397b3c25289d7541b077ff6d374b7bda4e4120cb/mounts/shm
- 磁盘IO:
iostatrkB/s每秒读取数据量kB
wkB/s每秒写入数据量kB
svctm I/O 请求的平均服务时间,毫秒
await I/O 请求的平均等待时间,毫秒
util 一秒钟有百分之几的时间用于IO操作,解决100%时,表示磁盘带宽跑满,需要优化程序或者增加磁盘
svctm await的值很接近,说明几乎没有IO等待,磁盘性能好,如果await 远高于 svctm,表示IO队列等待过长,需要优化程序或者增加磁盘
查看额外
pidstat -d 采样间隔秒数 -p 进程号
[root@iZbp1f96jelc5vbwqq8habZ ~]# iostat -xdk 2 3
Linux 4.18.0-193.28.1.el8_2.x86_64 (iZbp1f96jelc5vbwqq8habZ) 08/19/2021 _x86_64_ (1 CPU)
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
vda 0.80 0.66 28.41 7.51 0.00 0.08 0.13 10.70 3.16 1.84 0.00 35.43 11.32 0.45 0.07
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
vda 0.00 0.50 0.00 5.97 0.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00 12.00 1.00 0.05
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
vda 0.00 1.00 0.00 13.25 0.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00 13.25 1.00 0.10
- 网络IO:
ifstat- 默认本地没有,需要下载ifstat
生产环境CPU占用过高的可能原因
需要结合JDK核Linux一起排查
- 1.先用top命令找出cpu占用最高的
- 2.ps -ef java 或者jps进一步定位,得知是一个什么后台程序获取进程号
[root@iZbp1f96jelc5vbwqq8habZ ~]# jps -l
3596983 sun.tools.jps.Jps
1326 /usr/lib/jenkins/jenkins.war
1806 gutley-0.0.1-SNAPSHOT.jar
79582 org.apache.rocketmq.namesrv.NamesrvStartup
[root@iZbp1f96jelc5vbwqq8habZ ~]# ps -ef|grep gutley|grep -v grep
root 1806 1 0 Feb25 ? 02:50:30 java -jar gutley-0.0.1-SNAPSHOT.jar --server.port=80
3.定位到具体线程或者代码
ps -mp 1806(jps查到的进程号) -o THREAD,tid,time- 找到cpu消耗最大的线程号
4.将需要的线程ID转换成16进制格式(英文小写格式)
printf "%x\n" 线程号
5.jstack进程ID|grep tid 16进制格式(英文小写格式)-A60
jstack 180(进程号) |grep 717(打印出来的16进制线程ID) -A60 (打印前60行)
jstack 1806 |grep 717 -A60
JDK自带的JMM监控和性能分析工具用法
//todo