
ElacticSearch进阶
集群部署
- 集群提供可扩展的容量,且高可用,并发处理高,生产环境应用运行在集群中
Windows集群
Linux集群
ES核心
接近实时 NRT
- ES是一个接近实时的搜索平台,这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(1s以内)
集群 cluster
- 一个集群就是由一个或者多个节点组织一起的,它们共同持有整个数据,并提供索引和搜索功能。一个集群由一个唯一的名字来标识,这个名字默认‘elactisearch’,这个名字是重要的,因为节点的加入必须指定某个集群的名字。
节点 node
- 集群包含多个节点,它参与集群的索引和搜索功能
- 节点也是有名称的,默认情况下是一个随机的漫威角色名,这个名字会在节点启动时赋予。节点名称对于管理也是重要的,在管理过程中,需要确定网络中哪些服务器对于集群中的哪些节点。
- 一个节点可以通过配置集群名称加入集群,如果你启动了若干节点,并假定它们彼此互相发现,那么它们就自动的形成并加入集群中。
分片 shards
- 分片:
- 分片就是,有一个大的索引,单节点没有这么大容量或者放单节点上处理搜索很慢,为了解决这个问题,es设置分片,允许一个索引放置在多个节点上。
- 分片很重要,主要的原因有两个:1)允许你水平分割/拓展你的内容容量 2)允许你分片(潜在地位于多个节点上)之上进行分布式,并行的操作,提高吞吐量
副本 replicas
- 在一个网络、云环境中,失败随时可能发生,在某个分片/节点挂掉时,有一个故障转移机制是非常有用的
- 某个节点挂了,有一个故障转移很重要。为此目的,ES允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者复制
- 复制很重要,主要的原因有两个:1)在节点失败的情况下,提供了高可用 2)拓展搜索量/吞吐量
- 复制不与原分片/主要分片置于同一节点是重要的
分配 allocation
- 将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由master节点完成的
系统架构
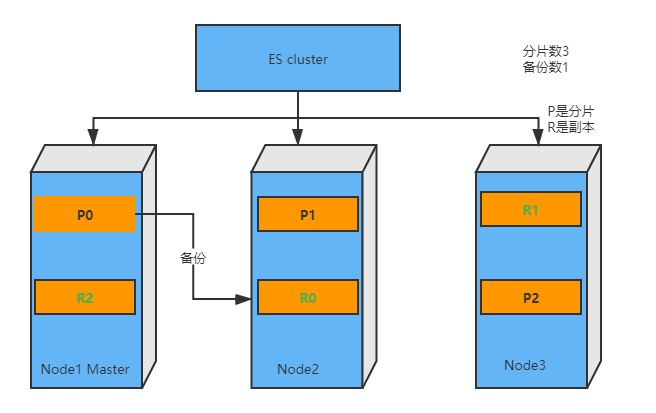
# 假设我们设置一个users的索引,设置三个分片,每个分片对应一个副本
curl -XPUT "http://localhost:9200/users/_settings" -d'
{
"settings":{
"number_of_shards:": 3,
"number_of_replicas": 1
}
}
'
故障转移
- 当集群只有一个节点时,意味着会有单点故障问题。
- 当你在同一台集群启动另一个节点,只要第二个节点具有相同的cluster.name,它会自动发现加入。
- 在不同机器上启动节点,为了加入集群,需要配置一个可连接到单播主机列表。之所以配置为使用单播发现,是防止其它节点无意中加入集群
水平扩容
- 水平扩容,当启动三个节点,为了分散负载会对分片进行重新分片
- 如果是一个或两个节点,三个分片每个节点都会有,当节点为三个,则三个分片会两两分配到三个节点上,保证每个节点上,任意一个分片异常,都有别的节点上副本提供备用
Tips
- 假设三个分片0、1、2,三个节点A、B、C
- A节点上分片 0、1
- B节点上分片 0、2
- C节点上分片 1、2
分片是一个功能完整的搜索引擎,它拥有使用的一个节点上所有资源的能力。我们现在拥有6个节点(3主分片,3副本分片)的索引最大可扩展到6个节点,每个节点上一个分片,并且每个分片拥有所在节点的全部资源。
如果我们想扩容超过6个节点怎么办?
- 主分片数目在索引创建时已经确定了(不可变),只有3个。这个定义的数目已经确定了数据存储的最大量(取决数据大小、硬件大小、使用场景)。但是读操作,是可以同时从主分片和副本分片处理。意味着,你可以扩展大的副本节点,使吞吐量变大
#条件副本分片为2,即三个分片拥有6个副本
curl -XPUT "http://localhost:9200/users/_settings" -d'
{
"number_of_replicas":2
}
'
# 这种情况下,极限节点数就是9台,3主+6副本
应对故障
- 假设从Node挂掉,只会影响分片数,不会影响数据的CRUD。从节点恢复以后,继续加入主节点
- 如果主Node挂掉,其它从Node会选举一个主Node,也不会影响数据的CRUD。挂掉的节点再加入就变成了从Node
ES的数据写入和读取
写入
- 客户端选择一个 node 发送请求过去,这个 node 就是
coordinating node(协调节点) coordinating node对 document 进行路由,将请求转发给对应的 node(primary shard)。- 实际的 node 上的
primary shard处理请求,然后将数据同步到replica node。 coordinating node如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。- 写入数据,判断写入哪个主分片叫做路由计算 :hash(id)%主分片数
- 客户端选择一个 node 发送请求过去,这个 node 就是
读取
- 可以通过
doc id来查询,会根据doc id进行 hash,判断出来当时把doc id分配到了哪个 shard 上面去,从那个 shard 去查询 - 客户端发送请求到任意一个 node,成为
coordinate node。 coordinate node对doc id进行哈希路由,将请求转发到对应的 node,此时会使用round-robin随机轮询算法,在primary shard以及其所有 replica 中随机选择一个,让读请求负载均衡。- 接收请求的 node 返回 document 给
coordinate node。 coordinate node返回 document 给客户端。
- 可以通过
倒排索引结构
- 前面提过,倒排索引就是根据value找key,为此我们举个例子
- 假设有个users索引,它有四个字段,分别是name|gender|age|address。画出来大概是个这个样子,以关系型数据库一样
id | name | gender | age | address
- | :-: | :-: | :-: | -: 1 | 张三 | 1 | 22 | 宝鸡市陈仓区 2 | 李四 | 2 | 21 | 西安市长安区
3 | 王五 | 1 | 23 | 西安市雁塔区
Term单词:一段文本经过分析器分析后输出的一串单词,就是一个个的TermTerm Dictionary字典:顾名思义,就是保存Term的字典。Posting List倒排列表:记录出现过某个Term的所有Documents文档列表以及该Term在文档位置,每条记录都称为一个倒排项Posting- 实际的Posting List不仅仅保存文档ID这么简单,还保存了其它信息,比如次频、偏移量等
Term Index单词索引:为了更好找到某个单词,我们为Term单词建立索引上面的例子,ES建立的索引大致如下:
- name字段
Term | Posting List |
| :-: | :-: | :-: | -: 张三 | 1 | 李四 | 2 | 王五 | 3 |
- age字段
Term | Posting List |
| :-: | :-: | :-: | -: 21 | 2 | 22 | 1 | 23 | 3 |
- gender字段
Term | Posting List |
| :-: | :-: | :-: | -: 1 | [1,3] | 2 | 1 |
- address字段
Term | Posting List |
- | :-: | :-: | :-: | -: 宝鸡市 | 1 | 西安市 | [2,3] |
陈仓区 | 1 |
雁塔区 | 3 |
长安区 | 2 |
- ES会为每个字段都建立一个倒排索引,上面的张三、西安市、22都是Term,而[2,3]就是Posting List,存储了所有符合某个Term的文档ID
- 如何根据关键词找到Term?这就需要给Term建立索引,类似MySQL的B+Tree结构
- 倒排索引中,我们根据Term索引可以找到Term在Term Dictionary的位置,进而找到Posting List,然后找到 Documents的ID
- 类比MySQL,Term Index可以理解为索引,Term Dictionary理解为数据
文档搜索
- 早期全文检索会为整个文档Documents建立一个很大的倒排索引并写入磁盘,一旦新的索引就绪,旧的会被替换,这样保证最近的变化可以被检索到
- 倒排索引写入磁盘后是不可改变的,目的如下:
- 不需要锁,因为没有写入,就只有读
- 索引被读入内核文件缓存,大部分的请求直接访问缓存,不会命中磁盘
- 其它缓存(filter缓存),在索引生命周期内始终有效,不需要每次数据改变被重建
- 写入单个大的倒排索引允许数据压缩,减少磁盘I/O和需要被缓存到内存的使用量
- 当然不变的倒排索引也有缺点,即创建后,如果要修改,就需要重建整个倒排索引,如果更新频率高,则性能有很大影响
- 如何保证不变性前提下实现倒排索引更新?
- 答案是:建立更多的倒排索引,即通过创建新的倒排索引来补充修改的内容,而不是直接全部重写。每个倒排索引都会被查询,合并后返回
- 逻辑删除:这样的话,一个倒排索引就可能包含多段,既然段不可改变,删除的数据也是不能真正在磁盘中删除的。所以我们会对删除的数据进行标记(逻辑删除)。这个缺点就会导致无效数据量可能累计过大。
- 合并:解决一个倒排索引中多个段无效数据过多的问题,对数据进行整理合并。
文档刷新&文档刷写&文档合并
- 近实时搜索:
- 随着按段(per-segment)搜索的发展,提交Commiting一个新的段到磁盘需要一个
fsync来确保数据写入磁盘。保证数据不丢失。但是这个操作代价很大,如果每个索引都执行一次开销很大。
- 我们有更轻量化方式使文档可被搜索。即修改的内容先在内存缓存区OS Cache中被写入一个新的段中。然后再被刷新到磁盘。到磁盘这一步代价较高,不过文件以及在缓存区OS Cache中了,就已经可以被读取。保证了近实时。
- 内存中数据写入到OS Cache过程叫refresh,效率很高。进入以后就可以提供给用户查询了,而写入磁盘的flush较慢。flush中包含了文档的合并
- 随着按段(per-segment)搜索的发展,提交Commiting一个新的段到磁盘需要一个
Tips
- 数据写入磁盘,协调节点找到主分片,并发写入副本分片
- 延时:主分片的延时+并行写入副本的最大延时
文档分析
文档分析包含以下过程
- 将一个词条分成合适的倒排索引独立的Term
- 将这些词条统一化成标准格式提高可搜索性
以上操作由分析器来操作,分析器实际是将三个操作封装到包里:
- 字符过滤器:字符串按顺序通过每个字符过滤器。它们任务是在分词前整理字符串。一个字符过滤器可以用来去掉HTML、或者将&转化成and
- 分词器:字符串会被分词器分为单个的Term,一个简单的分词器遇到空格或者标点时,可能会对文本拆分
- Token过滤器:词条按顺序通过Token过滤器,这个过程可能会改变词条(例如,Like变小写),删除词条(例如a、the、and无效词条),或者增加词条(例如,jump和leap这种同义词)
内置分词器
- ES提供了一些预装的分词器,主要的如下:
- 标准分词器:这是ES的默认分词器。它分析各种语言最常用文本选择,删除绝大部分标点,将词条小写。
- 简单分词器:在任何不是字母的地方进行分隔,词条小写
- 空格分词器:在空格的地方分词
- 语言分析器:特定语言分析器可用于多种语言,它可以考虑语言特点,例如分析英语中无效的a\the\and等
- ES提供了一些预装的分词器,主要的如下:
分析器使用场景
- 当我们索引一个文档,它的全文域会被分析成Term来创建倒排索引。但当我们用全文域搜索时。需要将查询字符串通过相同的分析过程,以保证我们搜索词条格式和索引中Term一致
# 检测分词器分词效果
curl -XGET "http://localhost:9200/_analyze" -d'
{
"analyzer":"standard",
"text":"Text to analyze"
}
'
# 返回结果中token是实际存储的Term,position记录Term在原始文本的位置,start_offset\end_offset记录偏移量
- 指定分析器IK
- 中文分词,采用IK分词器,下载地址 https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v7.8.0
- 解压文件放入ES根目录下plugins目录下,重启ES
- 测试效果
# ik_max_word将文本拆成最细粒度的
curl -XGET "http://localhost:9200/_analyze" -d'
{
"analyzer":"ik_max_word",
"text":"中国人"
}
'
# ik_max_word中Term会分为`中国人` `中国` `国人`
#ik_smart 将文本最粗粒度拆分
curl -XGET "http://localhost:9200/_analyze" -d'
{
"analyzer":"ik_smart",
"text":"中国人"
}
'
#ik_smart中Term只有一个就是`中国人`
- ES也可以自己对分词进行扩展
- 进入ES的plugins目录的ik文件夹,进入config目录,创建custome.dic文件,写入自定义分词
- 打开IKAnalyzer.cfg.xml文件,将新建custom.dic配置其中,然后重启ES
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
文档控制
- 文档冲突:当我们使用index API更新文档,可以一次性读取原始文档,做修改。然后重新索引整个文档。最后的索引请求将被执行。如果同时他人也在更改整个文档,他们的更改会丢失。
- 如果是全量更新,最终执行的是一个人的修改数据。如果是局部更新,可能A成员改了a部分数据,B成员改了b部分数据,这就有问题了。
- 悲观并发控制:这种方式在关系型数据库被广泛使用,简单来说就是操作数据时,对资源加锁
- 乐观并发控制:ES假设这种冲突不太可能发生,并且不会阻塞数据操作。如果源数据读写过程中被修改,更新将会失败,应用程序将决定如何处理失败。例如尝试更新、使用新的数据,或者将问题报告给用户 。
- put文档时,会返回
_seq_no和_primary_term字段,用来做乐观锁(老版本用version)
- put文档时,会返回
curl -XPOST "http://localhost:9200/shopping/_doc/1001?if_seq_no=0&if_primary_term=1" -d'
{
"name":"华为",
"price":"4999"
}
'
#还有一种用version的方式,即你的version需要大于文档的version
curl -XPOST "http://localhost:9200/shopping/_doc/1001?version=3&version_type=external" -d'
{
"name":"华为",
"price":"4999"
}
'
文档展示-kibana
- 下载安装kibana
- 修改配置config/kibana.yml文件
#默认端口
server.port:5601
#配置ES服务器地址
elasticsearch.hosts:["http://localhost:9200"]
#索引名
kibana.index:".kibana"
#支持中文
i18n.locale:"zh-CN"